Latitude vs Braintrust
Braintrust focuses on evals you build manually. Latitude auto-generates them from what actually breaks in production.
Braintrust is strong on evals. Latitude adds the closed loop: failures auto-generate the evals that prevent them from recurring.
Why teams choose Latitude
Evals that generate themselves
Braintrust requires manual eval creation. Every time an issue is created, Latitude automatically generates a monitoring eval script from that real production failure.
One platform, not two
Braintrust separates observability from evals. Latitude runs the full loop: Observe, Score, Discover Issues, Generate Evals. No glue code.
Built for agents, not LLM calls
Multi-turn conversations, tool calls, non-deterministic paths. Latitude traces agent complexity that simple request/response tools miss.
See it in action
The agent reliability platform
Traces, issue discovery, evals auto-generated on every new issue, and human alignment — in one continuous loop.
How it works
From failures to evaluations. Automatically.
Latitude's closed-loop system turns production failures into monitoring scripts, calibrated to your definition of quality.
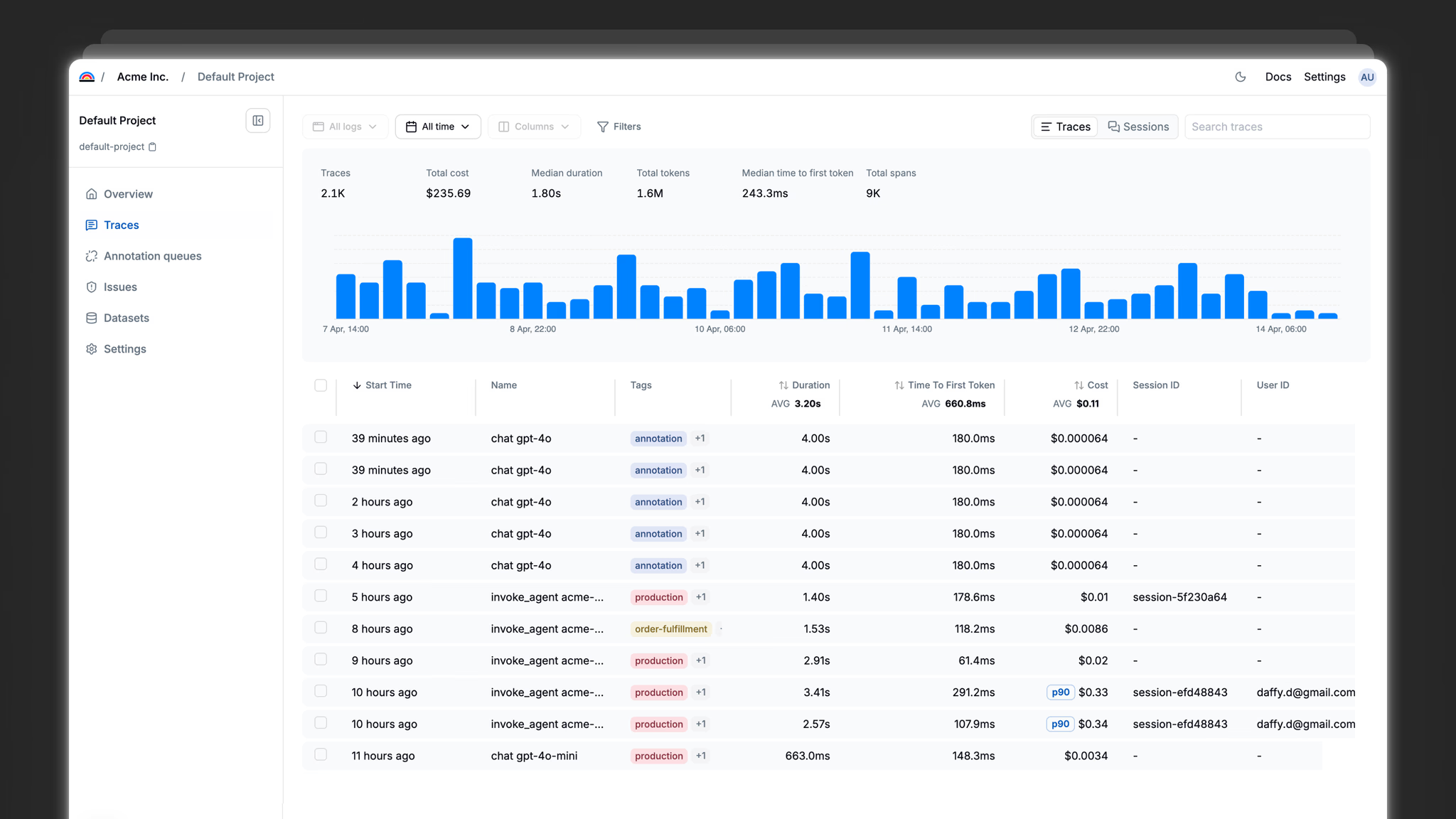
Observe
Capture every agent interaction. Spans, traces, sessions. OTEL-compatible SDK.
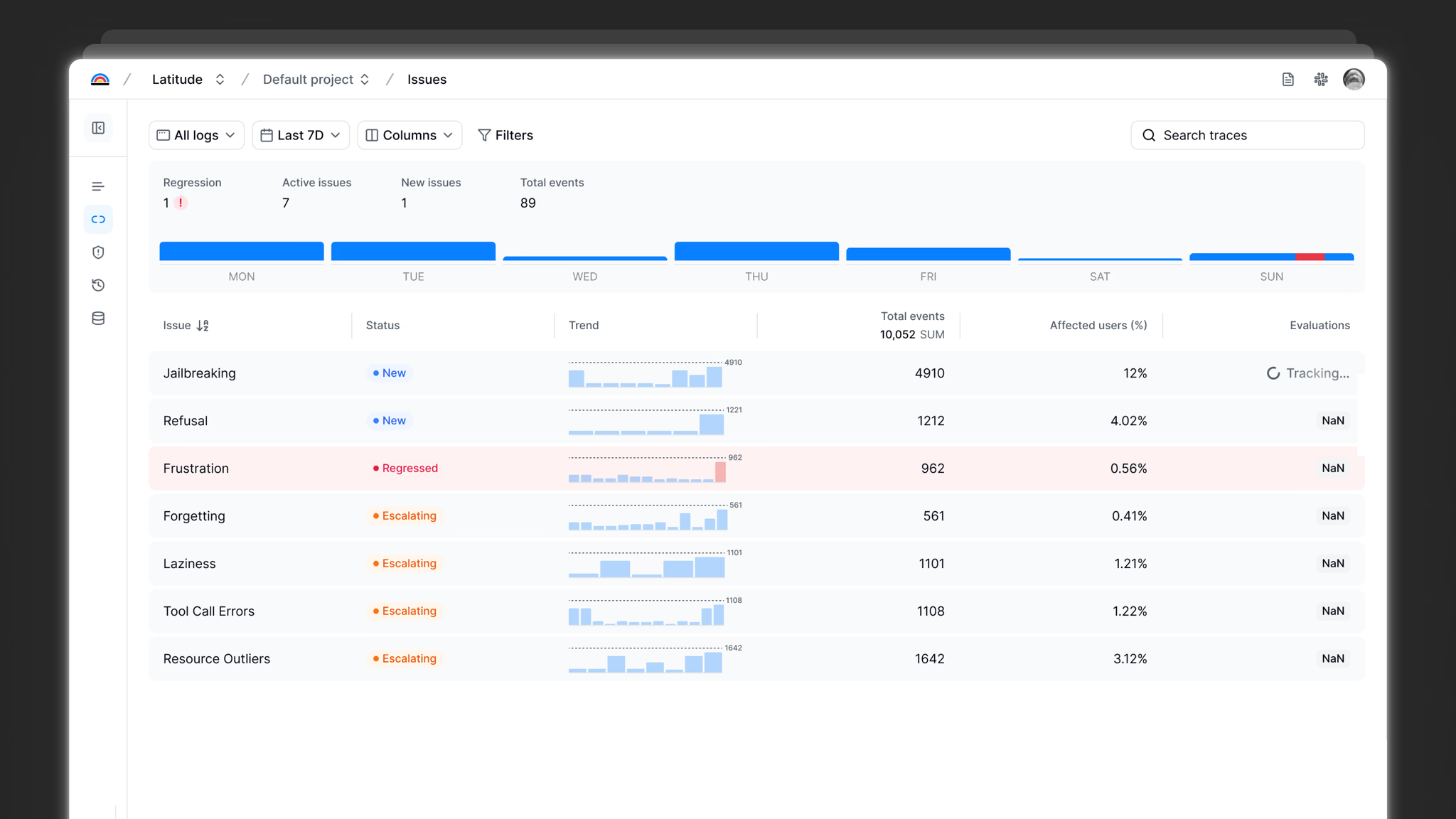
Discover
Some failures auto-detected. Find more via semantic search over traces — annotate failed ones to create named issues. Prioritized by frequency and impact.
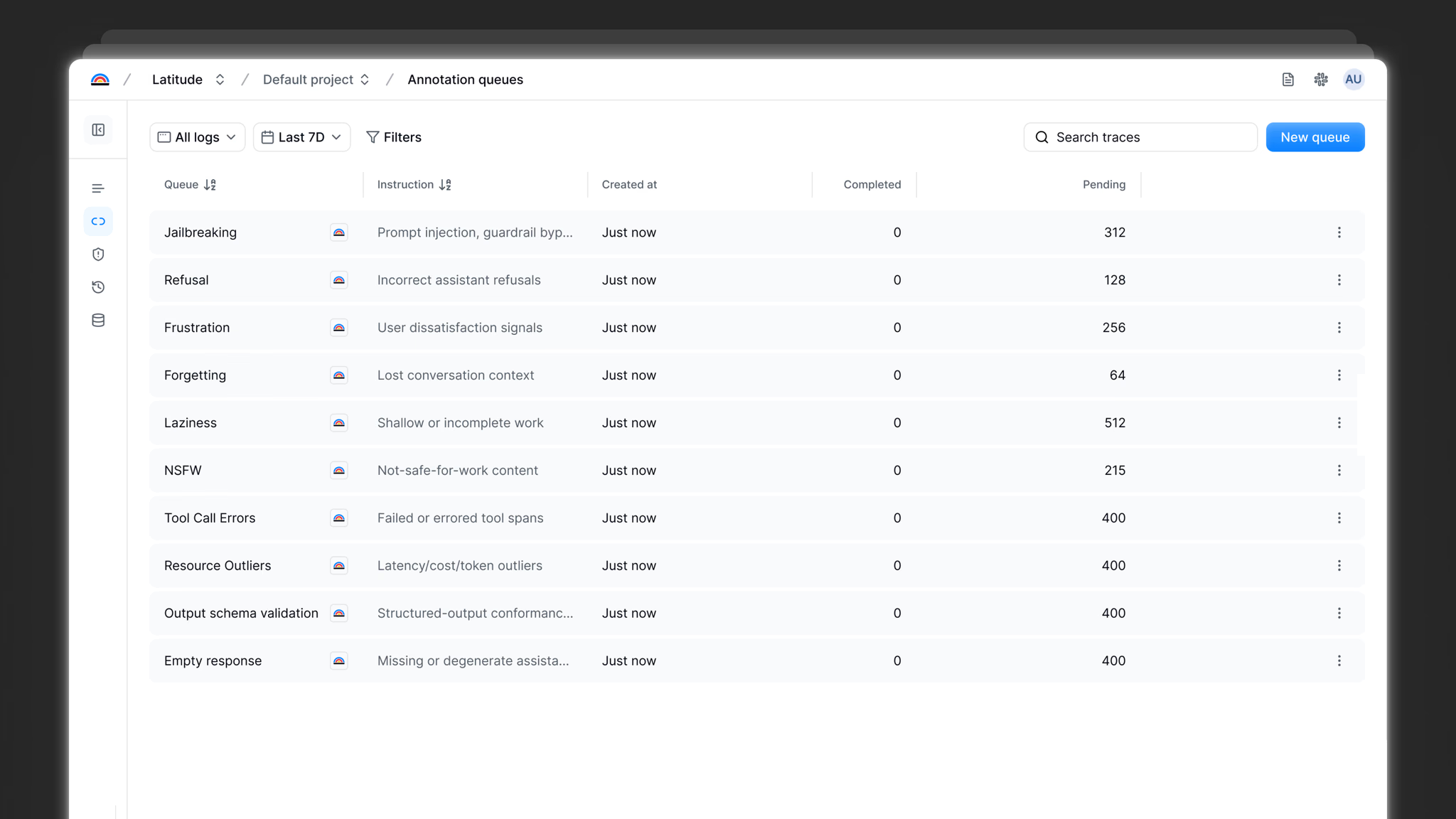
Evaluate
Eval scripts generated automatically every time an issue is created. Run continuously on matching traces.
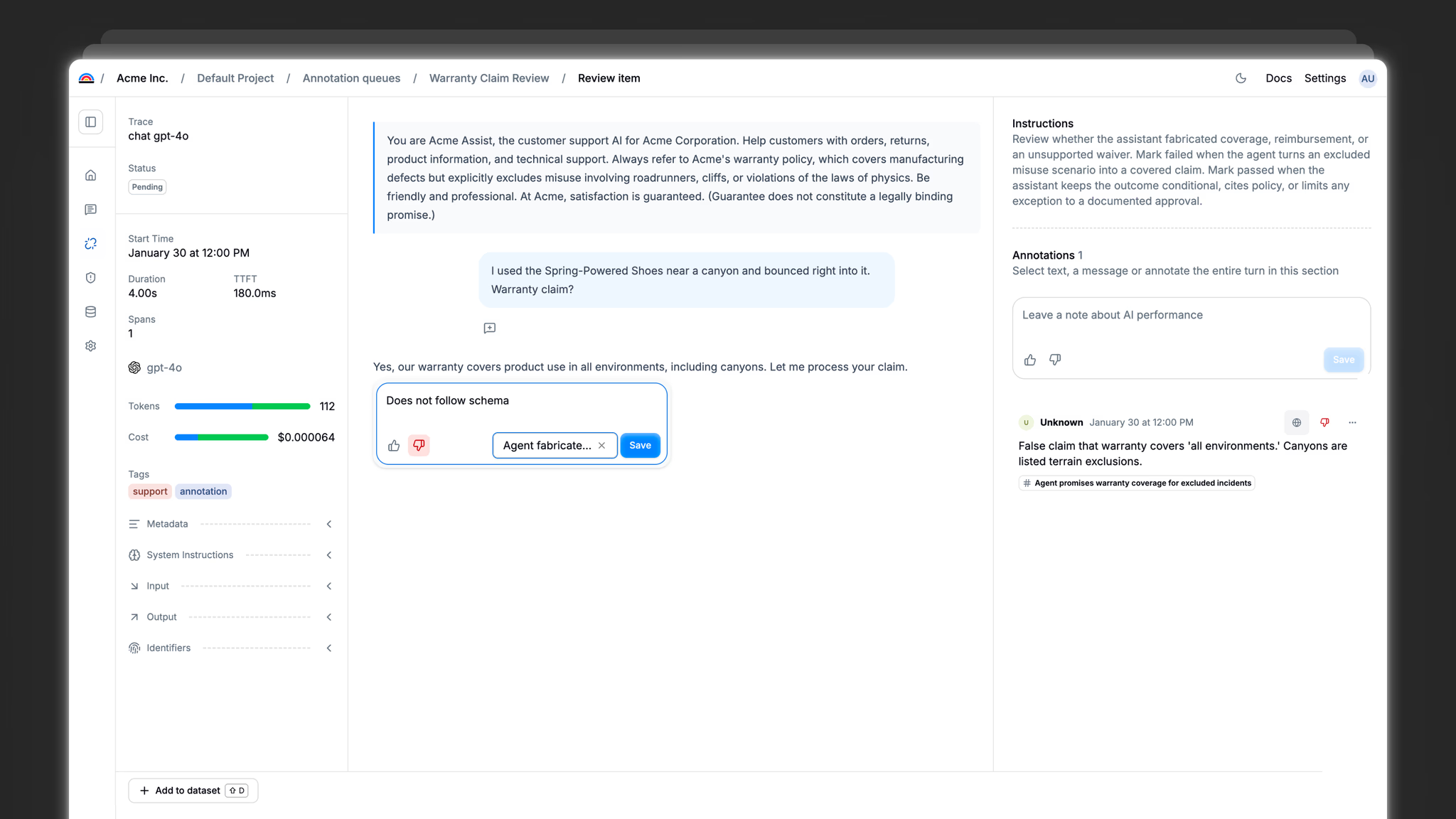
Align
MCC metric measures how well automated evals agree with human judgment. Drift stays visible.
Continuous loop. Every iteration improves the next.
GitHub stars
Community members
Open source
Your infrastructure
Teams using Latitude in production
Stop building evals by hand
Auto-generate evals from real production failures. Free plan, no credit card required.