For AI teams shipping agents to production
LLM Evaluation Built for AI Agents
Evaluations auto-generated for every new issue from real production failures, not synthetic benchmarks. Calibrated to your team's judgment via human annotations.
Trusted by thousands of engineers at companies like
The problem
Your agents fail silently. You find out from users.
Production AI is non-deterministic. Traditional testing catches the easy cases. The hard failures reach your customers first.
Invisible failures — no alerts, no clustering, just user complaints
Generic benchmarks — standard evals miss edge cases and tool-call errors
Built for LLMs, not agents — multi-turn, tool use, non-deterministic paths
The GEPA system
How GEPA works: from failures to evaluations, automatically
Latitude's closed-loop system turns production failures into monitoring scripts, calibrated to your definition of quality.
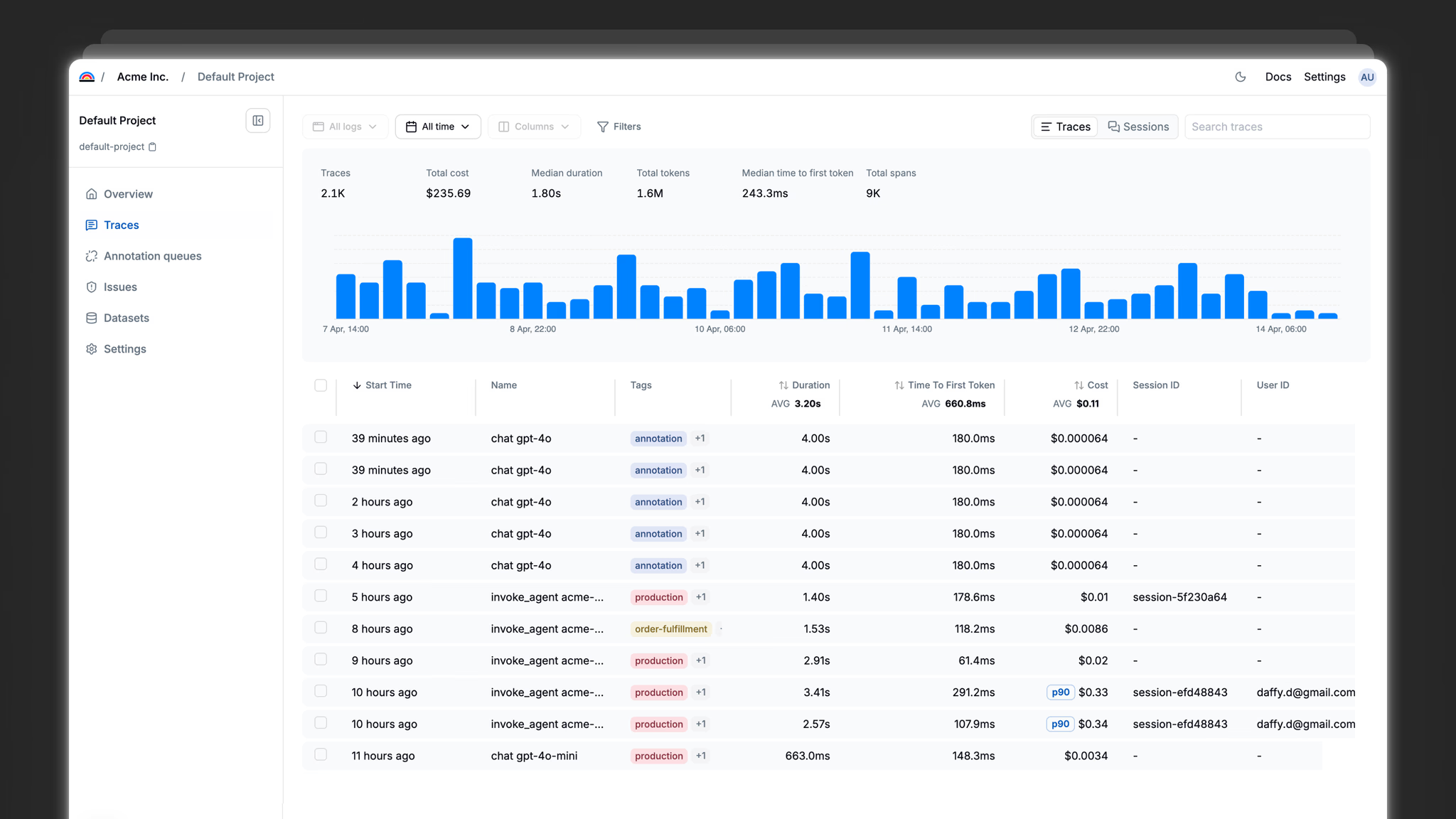
Observe
Capture every agent interaction. Spans, traces, sessions. OTEL-compatible SDK.
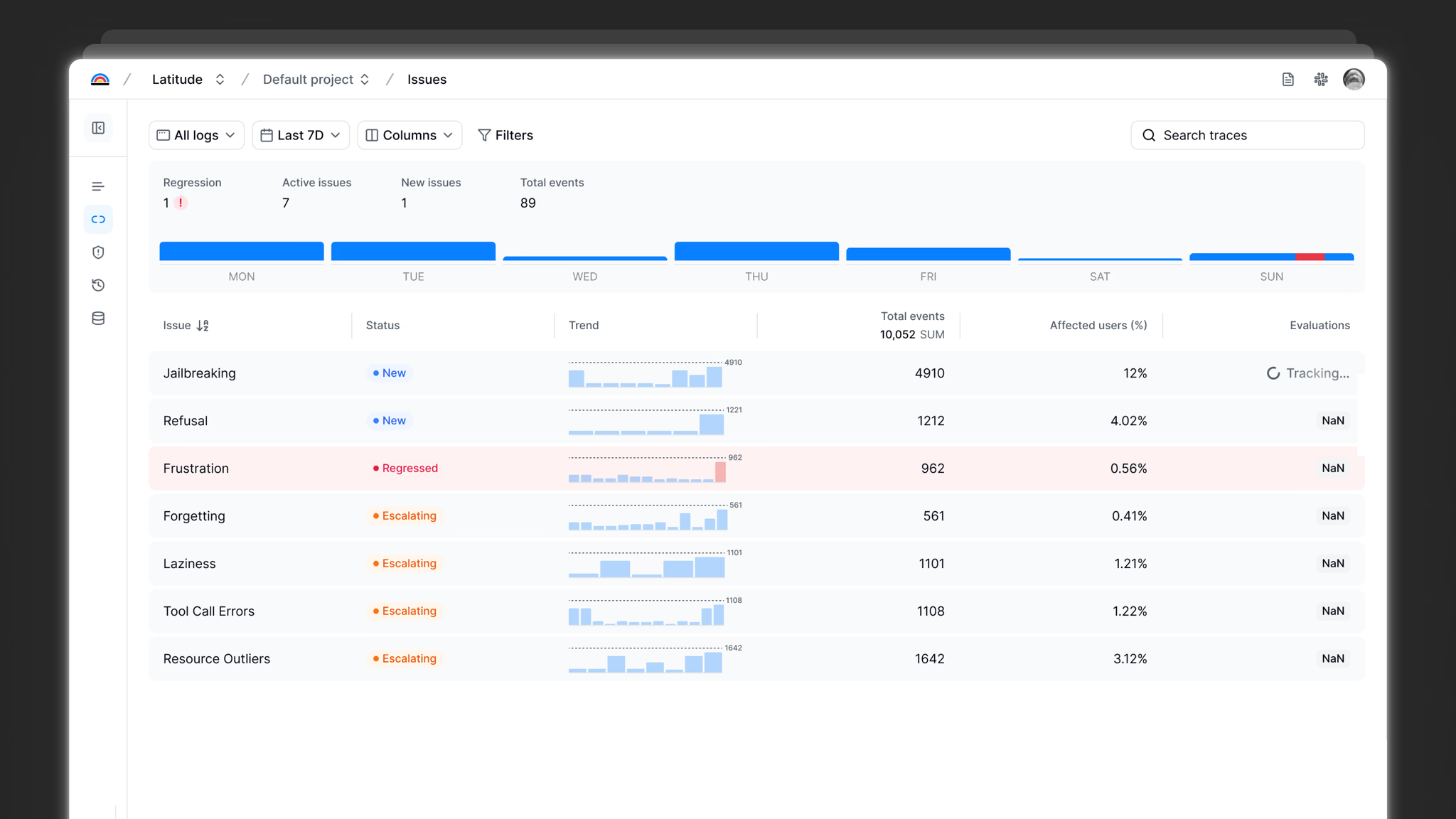
Discover
Some failures auto-detected. Find more via semantic search over traces — annotate failed ones to create named issues. Prioritized by frequency and impact.
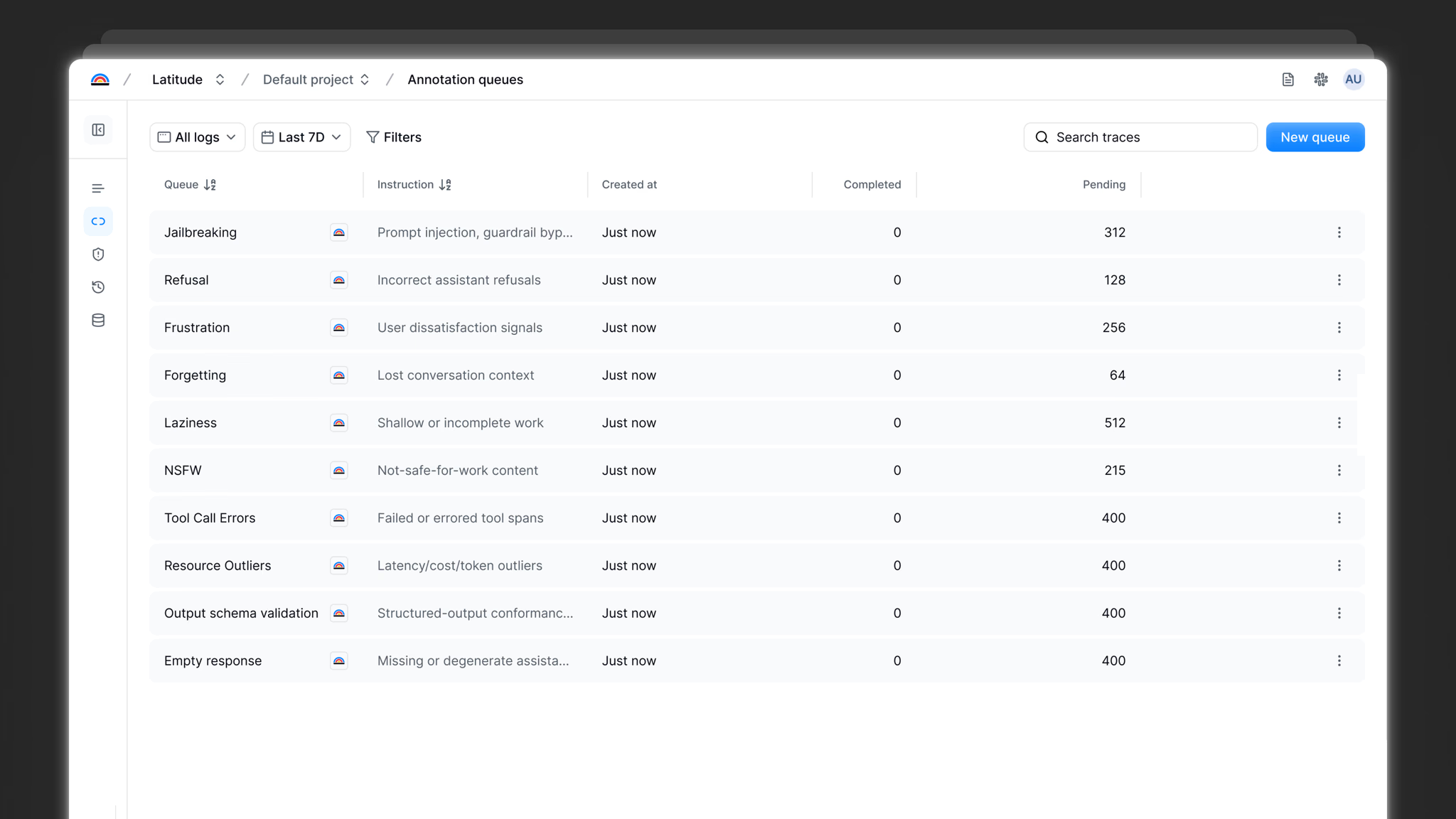
Evaluate
Eval scripts generated automatically every time an issue is created. Run continuously on matching traces.
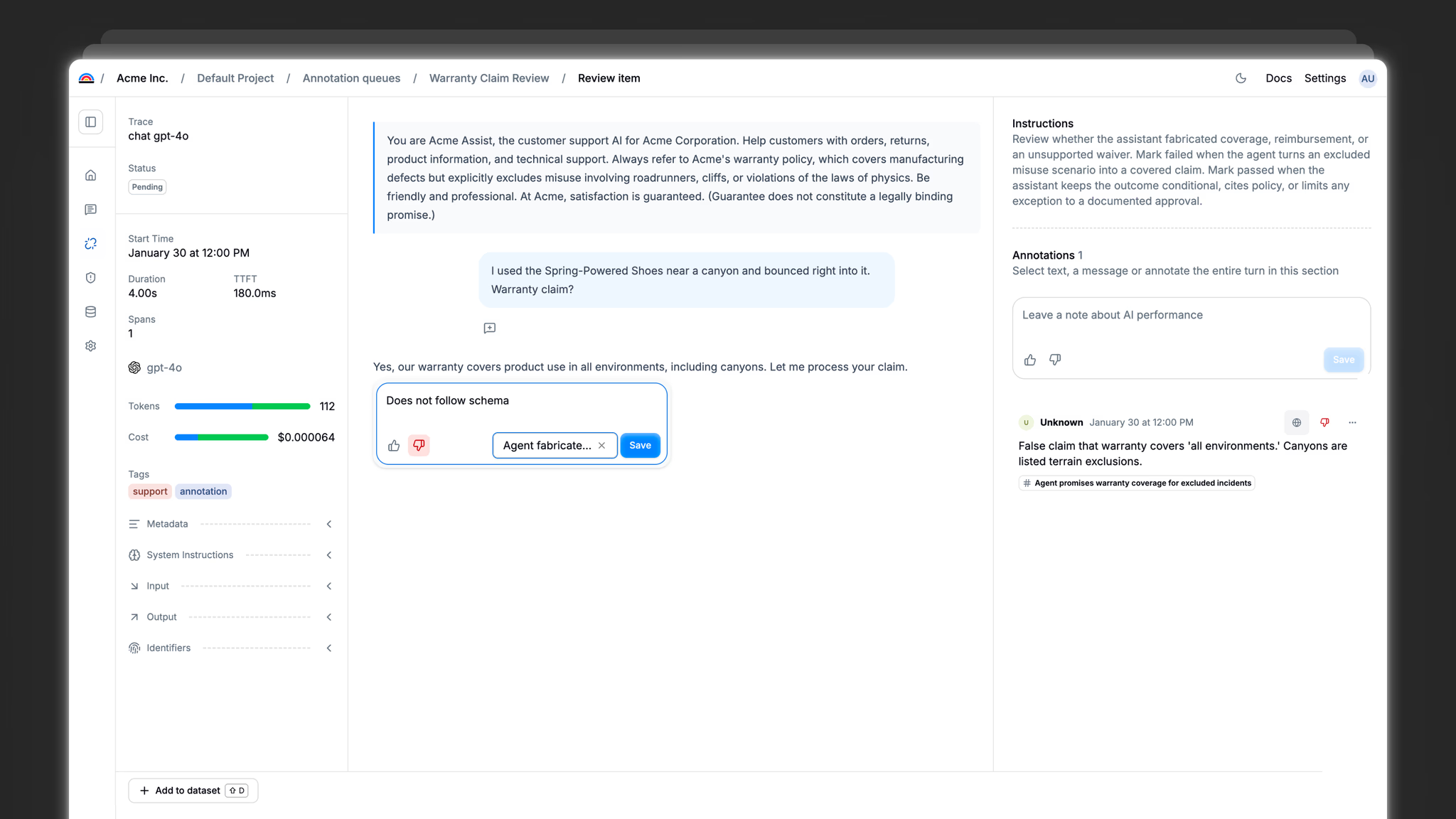
Align
MCC metric measures how well automated evals agree with human judgment. Drift stays visible.
Continuous loop. Every iteration improves the next.
Multi-turn agent support
Built for multi-turn agents, not just LLM calls
Traditional tools were designed for simple request/response. Agents are different — multi-turn conversations, tool use, non-deterministic paths. Latitude was built for this from day one.
Traditional tools
-
Simple request/response
Single LLM calls only. No multi-turn support.
-
Static benchmarks
Generic test suites disconnected from production reality.
-
Manual eval writing
Engineers write every evaluation by hand. Maintenance nightmare.
-
Log dumps, not insights
Scattered traces. You spot patterns manually or not at all.
Latitude
-
Multi-turn agent workflows
Sessions, tool calls, complex state. Native support.
-
Evals from real failures
Auto-generated on issue creation. Not synthetic benchmarks.
-
Issue discovery + lifecycle
Some auto-detected, others found via semantic search. Named, prioritized, tracked (New → Escalating → Resolved).
-
Human-calibrated scoring
Annotations + MCC alignment keeps evals honest.
Integrations
Works with your stack. Setup in minutes.
OTEL-compatible SDK for TypeScript and Python. Pick your provider and framework below to see your exact setup code.
LLM Providers
Agent Frameworks
Trusted in production
Open source. Production tested. Community driven.
4,000+
GitHub stars
1,200+
Community members





 Slack
Slack Self-host
Your infrastructure, full control
Commercial license available
8+
LLM providers
5+
Agent frameworks
OpenAI, Anthropic, LangChain, Vercel AI SDK, Mastra
MIT
Open source license
Full source on GitHub
Teams using Latitude in production
Pricing
Start free. Scale when you need to.
Unlimited seats on every plan. No per-user pricing.
Starter
- 20K credits/month
- Unlimited seats
- 30-day retention
- Full observability + evals
Pro
- 100K credits/month
- Unlimited seats
- 90-day retention
- $20 per 10K extra credits
Enterprise
- Custom volume
- Custom retention
- SAML SSO, on-prem
- SOC2, ISO 27001
Stop shipping AI blindly
See what's failing. Fix it systematically. Free plan, no credit card required.